「商品画像のタグ付けを自動化したい」「紙の帳票をデジタルデータに変換したい」。こうした業務課題の解決策として注目されているのが、AWSの画像認識サービスです。
AWSでは、あらかじめ学習済みですぐに使える「Amazon Rekognition」をはじめ、独自のAIモデルを構築できる「Amazon SageMaker」、文字抽出に特化した「Amazon Textract」など、目的に応じたサービスが用意されています。
本記事では、各サービスの特徴や料金、使い分けから導入ステップまで、初めてAWSの画像認識を検討する方にもわかりやすく解説していきます。


AWS画像認識とは?導入前に知るべきポイント
AWSの画像認識サービスを正しく理解するために、まず押さえておきたい基本事項があります。本章では、以下の3つの観点から解説していきます。
- クラウド画像認識と他の画像処理システムの違い
- AWSの画像認識が選ばれる理由
- AWS画像認識で解決できる業務課題
「クラウド画像認識」他の画像処理システムとの違い
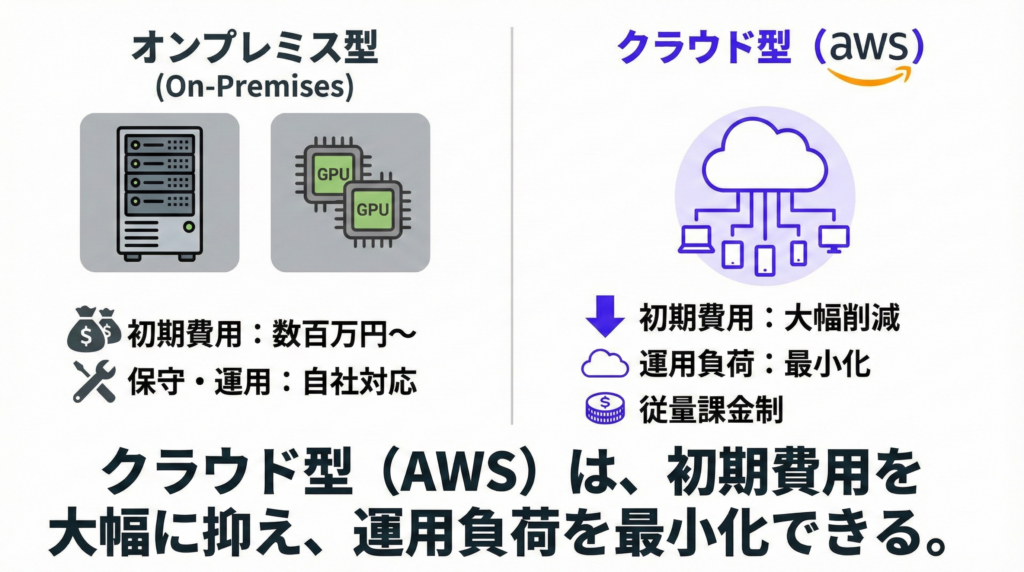
画像認識の仕組みには、大きく分けて「クラウド型」と「オンプレミス型(自社サーバー型)」の2種類があります。
オンプレミス型は、自社でサーバーやGPU(画像処理を高速に行う専用チップ)を用意し、その上にAIモデルを構築する方法です。
処理速度やセキュリティを自社でコントロールできる反面、初期費用が数百万円規模になることも珍しくありません。加えて、サーバーの保守やソフトウェアの更新も自社で対応する必要があり、運用負荷が大きくなりがちです。
一方、AWSのようなクラウド型は、インターネット経由でAIの機能を呼び出す仕組みとなっています。自社でサーバーを持つ必要がなく、初期費用を大幅に抑えられるのが魅力です。
使った分だけ課金される従量制のため、小さく始めて徐々にスケールさせるといった柔軟な運用もできるでしょう。
また、従来型のルールベース画像処理(「この色がこの範囲にあれば不良品」といった条件を人間が手動で設定する方式)と比べると、クラウド型AI画像認識は複雑なパターンも自動で学習・判別できる点が大きな違いといえます。
なぜAWSの画像認識がよいのか
クラウド型の画像認識サービスは、AWSのほかにもGoogle Cloud(Cloud Vision AI)やMicrosoft Azure(Computer Vision)が提供しています。その中でAWSが選ばれやすい理由は、主に3つです。
1つ目は、サービスの選択肢が豊富なこと。 AWSでは、すぐに使える汎用API(Amazon Rekognition)、独自モデルを構築できるプラットフォーム(Amazon SageMaker)、文字抽出に特化したサービス(Amazon Textract)と、用途に応じて最適なサービスを選び分けることができます。
2つ目は、既存のAWSインフラとの連携が容易な点。 すでにAWSでサーバーやデータベースを運用している企業であれば、画像認識サービスを追加する際の構築コストが低く済みます。S3(クラウドストレージ)に保存した画像をそのまま分析にかけるといったシームレスな連携が実現できるのは大きなメリットでしょう。
3つ目は、日本語ドキュメントとサポート体制が充実していること。 AWSは日本国内のシェアが高く、公式ドキュメントの日本語対応も進んでいます。導入事例やコミュニティの情報量が多いため、トラブル発生時にも情報を見つけやすいはずです。
AWS画像認識で解決できる業務課題
AWSの画像認識は、幅広い業務課題に対応できます。ここでは代表的な活用シーンをいくつか紹介します。
商品管理やECサイトの運営では、大量の商品画像にカテゴリやタグを自動付与することで、手作業による分類の手間を大幅に削減可能。商品登録のスピードアップや検索精度の向上にもつながります。
帳票や書類のデジタル化も代表的なユースケースです。紙の請求書や申込書をカメラで撮影し、記載内容をテキストデータとして自動抽出すれば、手入力の工数とミスを同時に減らすことができます。
セキュリティや本人確認の領域では、顔認識による入退室管理やオンラインでの本人確認(eKYC)に活用されるケースが増えてきました。Amazon Rekognitionには顔の「生体判定」機能もあり、写真や動画によるなりすましの防止にも対応できます。
品質管理や外観検査では、製造ラインの画像をAIが分析し、傷や欠陥を自動検出する仕組みを構築できるように。ただし、高い精度が求められる検査では汎用APIだけでは不十分なケースもあるため、SageMakerで独自モデルを構築する選択肢も検討する必要があるでしょう。
このように、AWSの画像認識サービスは「どの業務課題を解決したいか」によって使うべきサービスが変わってきます。次章以降では、主要な3サービスそれぞれの特徴や得意分野、料金を詳しく見ていきましょう。
Amazon Rekognition:事前学習済みですぐに使えるAI
Amazon Rekognitionは、AWSが提供する画像・動画分析サービスです。あらかじめ大量のデータで学習済みのAIモデルが用意されているため、機械学習の専門知識がなくても、API(外部からサービスの機能を呼び出す仕組み)を通じてすぐに画像認識を始められます。
本章では、以下の3つの観点からRekognitionの特徴を詳しく見ていきます。
- 汎用APIの認識能力と対応範囲
- 得意な用途と不向きな用途
- 料金体系の目安
1,000種類以上の物体を即座に認識する汎用API
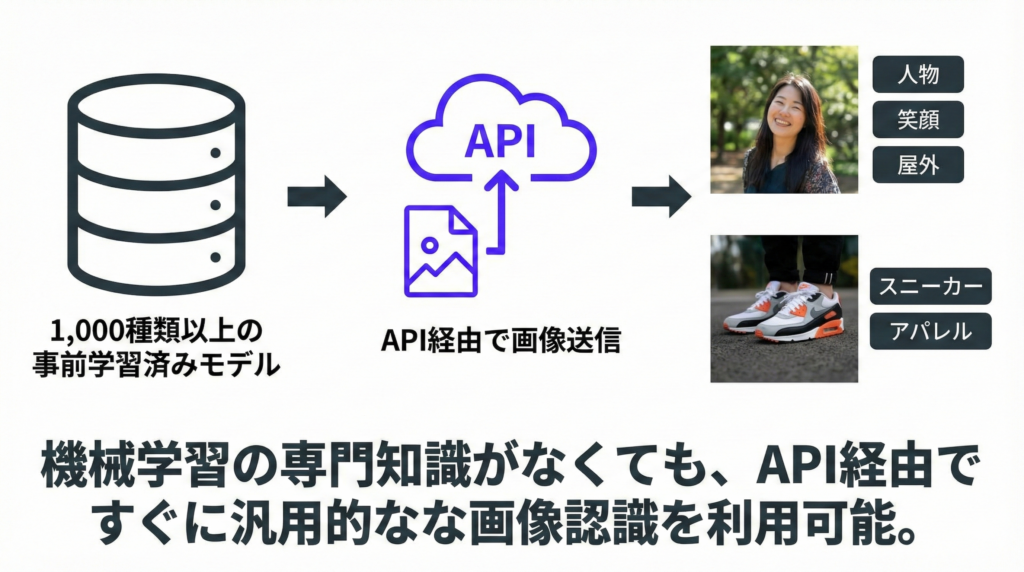
Amazon Rekognitionの最大の特徴は、事前学習済みモデルによる幅広い認識能力です。人物、動物、乗り物、食品、家具など1,000種類以上の物体やシーンを識別でき、画像をAPIに送るだけで数秒以内に結果が返ってきます。
主な機能としては、まずラベル検出があります。画像に写っている物体やシーンを自動でタグ付けし、「車」「犬」「屋外」といったラベルが信頼度スコア付きで返されるものです。
次に顔の検出・分析では、顔の位置を検出したうえで、年齢の推定範囲や感情(笑顔・驚きなど)、目が開いているかといった属性を分析してくれます。
さらに、暴力的・性的なコンテンツを自動で判定する不適切コンテンツの検出や、画像や動画に映る著名人を識別する有名人の認識といった機能も備わっています。
これらの機能はすべてAPIとして提供されており、必要な機能だけを組み合わせて使えるのも大きなメリットです。開発チームがゼロからAIモデルを構築する必要がないため、導入までのスピードが圧倒的に速いのが強みといえるでしょう。
EC商品タグ付けは最適、製造検査は不向き
Rekognitionは万能ではなく、得意・不得意がはっきりしています。導入前にこの点を理解しておくことが、失敗を防ぐうえで非常に大切です。
得意な用途としてまず挙げられるのが、ECサイトの商品画像タグ付けです。アパレルや雑貨など、一般的な物体を大量に分類する作業はRekognitionの汎用モデルと相性が良く、手作業と比べて大幅な効率化が期待できます。
また、SNSやコミュニティサイトにおける不適切画像のフィルタリング、オンラインでの本人確認(eKYC)なども得意分野。こうした「一般的な物体・人物の認識」が求められるシーンでは、高い精度を発揮してくれるはずです。
一方、不向きな用途の代表例が製造ラインでの外観検査です。たとえば「基板の微細なはんだ不良を検出したい」「食品の表面にある0.1mm単位の異物を見つけたい」といったケースでは、汎用モデルの精度では不十分な場合がほとんど。
このような専門的な判定が必要な場面では、自社の検査画像データを使って独自モデルを構築できるAmazon SageMaker(次章で解説)の方が適しています。
なお、Rekognitionにも「カスタムラベル」という独自モデル構築機能がありますが、SageMakerほどの柔軟性はありません。カスタムラベルは「既存のRekognitionモデルに少量の画像で追加学習させる」イメージで、比較的シンプルな分類タスクに向いています。高度なカスタマイズが必要かどうかで、どちらを選ぶか判断するとよいでしょう。
画像1,000枚120円、月10万枚で8,000円の従量課金制
Amazon Rekognitionの料金は、処理した画像や動画の量に応じた従量課金制です。初期費用や月額固定費はかからないため、スモールスタートしやすい料金体系になっています。
画像分析(Rekognition Image)の主な料金目安は以下のとおりです(東京リージョン、2025年5月時点の参考値)。
| 月間処理枚数 | 1枚あたりの単価(目安) | 月額費用の目安 |
|---|---|---|
| 最初の100万枚まで | 約0.0013ドル(約0.19円) | 1,000枚で約120円 |
| 100万〜1,000万枚 | 約0.001ドル(約0.15円) | 10万枚で約8,000円 |
| 1,000万枚超 | 約0.0004ドル(約0.06円) | さらに単価が下がる |
※為替レートや料金改定により変動する可能性があるため、最新の正確な料金はAWS公式サイトで確認してください。
処理枚数が増えるほど単価が下がるボリュームディスカウント方式のため、大量の画像を扱うほどコストメリットが大きくなる仕組みです。
動画分析(Rekognition Video)やカスタムラベルの学習・推論にはそれぞれ別の料金体系が設定されています。また、AWSには無料利用枠があり、初回利用から12か月間は月5,000枚の画像分析と月1,000分の動画分析を無料で試せるため、まずはこの範囲内で精度や使い勝手を検証してみることをおすすめします。
■少しでもAI・システム開発やPoCに興味があれば、まずはお気軽にご相談ください。目的・課題を伺ったうえで、弊社から手堅く進める方法・お見積りをお伝えさせていただきます。
AIシステム開発サービスのお問い合わせはこちら>>
AIシステム開発サービス概要資料のダウンロードはこちら>>
AIシステム開発サービスの詳細はこちら>>
AIシステム受託開発
相談だけで発注しなくても構いません。

Amazon SageMaker:独自モデルで高度な分析・カスタムを実現
Amazon SageMakerは、自社独自のAIモデルを構築・学習・運用できる機械学習プラットフォームです。前章で紹介したRekognitionが「すでに出来上がったAIをそのまま使う」サービスであるのに対し、SageMakerは「自分たちのデータを使ってAIを一から育てる」ためのサービスといえます。
本章では、以下の3つのポイントからSageMakerの特徴を解説します。
- SageMakerの基本的な仕組みと位置づけ
- 実現できる精度と開発にかかる期間
- 料金体系の目安
自社データで独自AIを構築する機械学習プラットフォーム
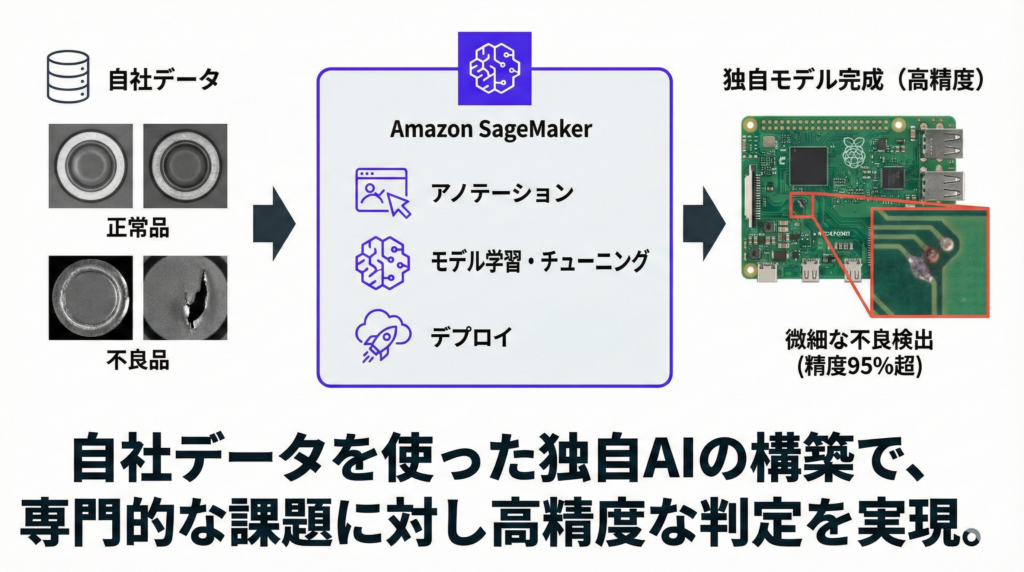
SageMakerの最大の強みは、自社が持つ画像データを使って、業務に最適化されたAIモデルを構築できることです。
たとえば、製造業で「自社製品特有の傷パターンを検出したい」というケースを考えてみましょう。Rekognitionの汎用モデルは一般的な物体の認識には優れていますが、特定の製品に固有の微細な不良を見分けるようには訓練されていません。
こうした場面で力を発揮するのがSageMakerです。自社の検査画像(正常品・不良品のサンプル)を大量に読み込ませ、「何が正常で何が不良か」をAIに学習させることで、汎用モデルでは対応できない専門的な判定が可能になります。
SageMakerが提供する主な機能としては、まずデータの前処理・加工が挙げられます。学習に使う画像データの整理やラベル付け(アノテーション)を効率的に行うツールが搭載されています。
次にモデルの学習・チューニングでは、複数のアルゴリズム(AIの学習手法)から最適なものを選び、パラメータを自動調整して精度を高めることが可能。さらにモデルのデプロイ・運用として、完成したモデルを本番環境に展開し、APIとして利用可能にする仕組みも提供されています。
つまり、AIモデルの「構築→学習→運用→改善」というライフサイクル全体をひとつのプラットフォームで完結できるのがSageMakerの特徴です。
ただし、SageMakerを使いこなすには機械学習やプログラミングに関する一定の知識が必要になります。
Rekognitionのように「APIを呼ぶだけ」というわけにはいかないため、社内にエンジニアがいない場合は、外部の開発パートナーと連携して進めるのが現実的な選択肢でしょう。
精度95%超も可能、ただし開発期間が2〜3ヶ月必要
SageMakerで独自モデルを構築した場合、業務要件に合わせたチューニングを行うことで、95%を超える高い認識精度を実現できるケースもあります。Rekognitionの汎用モデルでは70〜80%程度の精度にとどまるような専門的なタスクでも、十分な学習データと適切なモデル設計があれば大幅な精度向上が見込めるでしょう。
ただし、高精度のモデルを完成させるまでにはそれなりの時間がかかる点に注意が必要です。一般的な開発スケジュールの目安は以下のとおりです。
| フェーズ | 主な作業内容 | 期間の目安 |
|---|---|---|
| データ準備 | 学習用画像の収集・ラベル付け・品質チェック | 2〜4週間 |
| モデル構築・学習 | アルゴリズム選定・学習実行・パラメータ調整 | 2〜4週間 |
| 評価・チューニング | テストデータでの精度検証・改善サイクル | 2〜4週間 |
合計すると、おおよそ2〜3ヶ月が標準的な開発期間となります。もちろん、対象とするタスクの難易度やデータの質・量によって前後するため、あくまで目安として捉えてください。
また、精度を大きく左右するのが学習データの質と量です。「画像は大量にあるが、ラベル付けがされていない」「不良品のサンプルが極端に少ない」といった状況では、データの整備だけで想定以上の時間とコストがかかることも珍しくありません。プロジェクト開始前に、手持ちのデータがどの程度使える状態にあるかを確認しておくことが成功のカギになります。
初期開発30万円〜、学習インスタンス時間150円〜、月額運用3万円〜
SageMakerの料金は、Rekognitionのような「画像1枚あたり◯円」というシンプルな体系ではありません。主に以下の3つの要素で構成されています。
① 学習(トレーニング)にかかる費用
AIモデルを学習させるためにクラウド上のコンピューティングリソース(インスタンス)を使用する時間に応じた課金です。たとえば、標準的なGPUインスタンス(ml.g4dn.xlargeクラス)の場合、1時間あたり約150円前後が目安となります。学習に10時間かかれば約1,500円、100時間なら約15,000円という計算です。
② 推論(本番運用)にかかる費用
完成したモデルを本番環境で常時稼働させる場合、推論用インスタンスの利用料が継続的に発生します。小規模な構成でも月額3万円程度〜が一般的で、処理量やレスポンス速度の要件に応じてスケールアップすればその分費用も増加していきます。
③ 初期開発にかかる人件費
SageMaker自体の利用料に加えて、モデル設計・データ整備・チューニングなどの開発作業にかかる人件費も見込んでおく必要があります。外部に開発を委託する場合、比較的シンプルなモデルであっても30万円〜、高精度が求められる複雑なモデルでは100万円以上になるケースも。
| 費用項目 | 目安 |
|---|---|
| 学習インスタンス利用料 | 時間あたり約150円〜 |
| 推論インスタンス(月額運用) | 月額約3万円〜 |
| 初期開発費(外部委託の場合) | 約30万円〜 |
Rekognitionと比較すると初期費用・運用費用ともに高くなりますが、その分、業務に特化した高精度なモデルを手に入れられるのがSageMakerの価値です。費用対効果の見極めが重要になるため、まずはPoCで小規模に試し、投資に見合う成果が見込めるかを確認してから本格導入に進むことをおすすめします。
Amazon Textract:画像やドキュメントからの文字抽出(OCR)
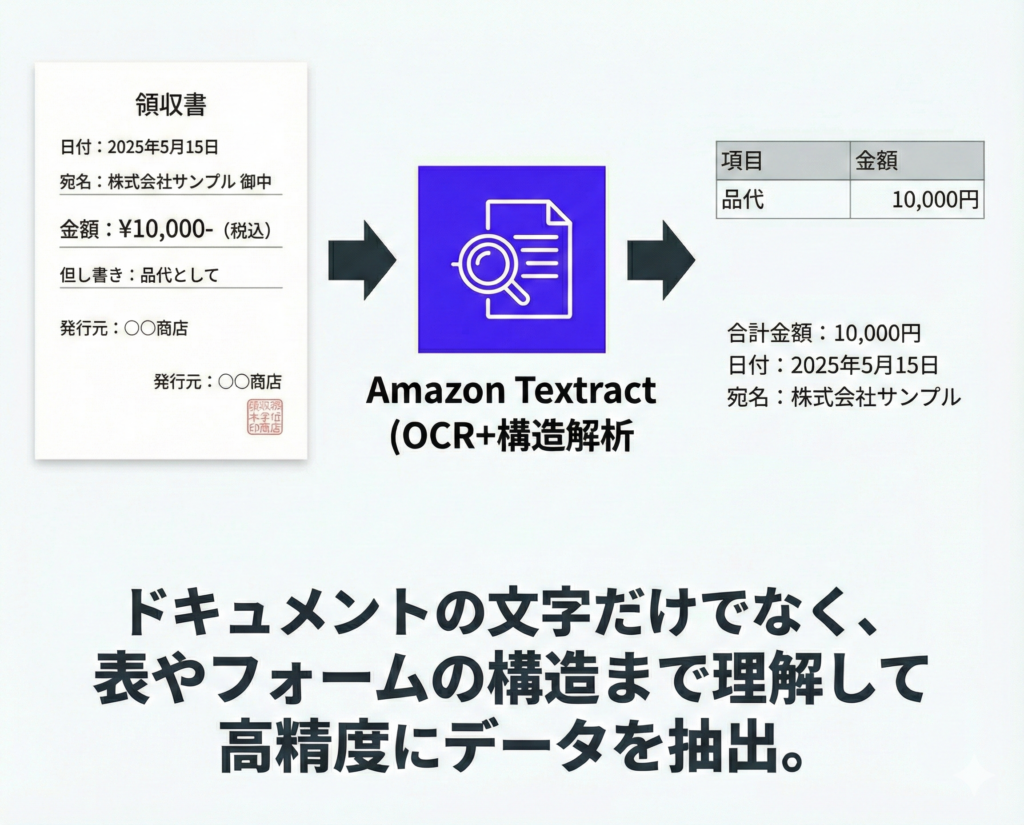
Amazon Textractは、画像やPDFなどのドキュメントから文字情報を自動で読み取るOCR(光学文字認識)サービスです。一般的なOCRツールとの違いは、単に文字を読み取るだけでなく、表やフォームの構造まで理解してデータを抽出できる点にあります。
本章では、以下の3つの観点からTextractの特徴を見ていきます。
- Textractの基本機能と活用シーン
- 文字抽出における他サービスとの使い分け
- 料金体系の目安
請求書・帳票を自動データ化するOCRサービス
Textractが特に力を発揮するのは、紙の書類やスキャン画像からのデータ入力業務を自動化したい場面です。
たとえば、毎月届く大量の請求書を手作業でExcelに転記している場合、Textractを使えば請求書の画像をアップロードするだけで、取引先名・金額・日付・品目などを自動的にテキストデータとして取り出せます。
手入力にかかっていた時間と人的ミスを大幅に削減できるのが最大のメリットでしょう。
Textractの主な機能としては、まずテキスト検出があります。画像やPDFに含まれる文字を検出し、プレーンテキストとして出力するもので、手書き文字の読み取りにも対応しています。
次に表(テーブル)の抽出では、表形式のデータを行・列の構造を保ったまま抽出できるため、Excelやデータベースへの取り込みもスムーズに行えます。さらに、請求書・領収書の専用分析機能も備わっており、合計金額・税額・支払先などの項目を高精度で抽出してくれます。
こうした機能を活用することで、経理部門での請求書処理、人事部門での入社書類のデジタル化、金融機関での本人確認業務など、幅広いバックオフィス業務の効率化につなげることが可能です。
文字抽出ならTextractが最優先
ここで気になるのが、「前章で紹介したRekognitionにもテキスト検出機能があるのでは?」という点です。確かにRekognitionにも画像内の文字を読み取る機能がありますが、両者には明確な役割の違いがあります。
Rekognitionのテキスト検出は、画像の中に映り込んだ文字を「物体のひとつ」として検出する機能です。看板に書かれた店名、道路標識の文字、商品パッケージのブランド名など、写真に写っている短いテキストの読み取りが主な用途で、あくまで画像認識の一機能という位置づけとなっています。
Textractは、ドキュメント全体を対象にした文字抽出に特化したサービスです。数百行に及ぶ文書の全文読み取り、表の構造解析、フォームのキー・バリュー抽出など、ビジネス文書のデータ化を前提に設計されています。
手書き文字への対応精度もRekognitionより高く、複雑なレイアウトの帳票でも構造を崩さずにデータを取り出せるのが強みです。
つまり、使い分けの判断基準はシンプル。「写真の中の文字を読みたい」ならRekognition、「書類や帳票をデータ化したい」ならTextractと覚えておけば、まず間違いありません。
また、SageMakerとの関係でいえば、Textractの標準機能でカバーできない特殊なフォーマット(たとえば、自社独自の検査票や特殊な手書き帳票など)に対応したい場合は、SageMakerで独自のOCRモデルを構築するという選択肢もあります。
ただし、多くの一般的なビジネス文書であればTextractの標準機能で十分対応できるため、まずはTextractから試してみるのが効率的でしょう。
1,000ページ150円、表認識は別途課金
Textractの料金は、処理するページ数と利用する機能に応じた従量課金制です。Rekognitionと同様に初期費用や月額固定費はかかりません。
主な料金の目安は以下のとおりです(東京リージョン、2025年5月時点の参考値)。
| 機能 | 1ページあたりの単価(目安) | 1,000ページあたり |
|---|---|---|
| テキスト検出(文字の読み取り) | 約0.0015ドル(約0.22円) | 約150円 |
| 表の抽出 | 約0.015ドル(約2.2円) | 約1,500円 |
| フォームの抽出 | 約0.015ドル(約2.2円) | 約1,500円 |
| 請求書・領収書の専用分析 | 約0.01ドル(約1.5円) | 約1,000円 |
※為替レートや料金改定により変動する可能性があるため、最新の正確な料金はAWS公式サイトで確認しましょう。
注意すべきポイントは、機能ごとに料金が加算される仕組みになっていることです。たとえば、1枚の請求書から「テキスト+表+フォーム」をすべて抽出する場合、3つの機能の料金がそれぞれ発生します。
単純な文字の読み取りだけなら非常に安価ですが、高度な構造解析を組み合わせると1ページあたりの単価が上がっていくため、事前にどの機能が本当に必要かを見極めることがコスト管理の鍵になるでしょう。
Textractにも無料利用枠が用意されており、初回利用から3か月間は月1,000ページまでの各種分析を無料で試せます。まずはこの範囲内で、自社の帳票に対する読み取り精度を検証してみることをおすすめします。
AWS画像認識サービスの導入を4ステップで解説
ここまで、AWS画像認識の主要3サービス(Rekognition・SageMaker・Textract)の特徴と料金を見てきました。本章では、実際にこれらのサービスを導入する際の具体的な進め方を、4つのステップに分けて解説します。
導入の全体像は以下のとおりです。
- ①課題の明確化とデータ準備(2〜4週間)
- ②最適サービスの選定とPoC設計(1〜2週間)
- ③PoC実施と精度評価(2週間〜1ヶ月)
- ④本番環境構築と運用開始(1〜3ヶ月)
すべてのステップを合計すると、最短で約2ヶ月、標準的には3〜6ヶ月程度が導入完了までの目安となります。それぞれのステップで何をすべきか、順番に見ていきましょう。
①課題の明確化とデータ準備(期間:2〜4週間)
最初のステップは、「そもそも画像認識で何を解決したいのか」を明確にすることです。ここが曖昧なまま進めてしまうと、サービスの選定を誤ったり、途中で目的がブレたりして、時間とコストを無駄にするリスクが高まります。
具体的には、以下のような問いに答えを出していく作業になります。まず、「解決したい業務課題は何か」を特定しましょう。「商品画像のタグ付けに毎月80時間かかっている」「請求書の手入力でミスが月に20件発生している」など、数値で把握できるとベストです。
次に、「画像認識で対応できる範囲はどこまでか」を見極めます。課題のすべてをAIで解決する必要はなく、最も効果が大きい部分に絞ることが大切です。
そして、「成功の基準をどこに置くか」を事前に設定しておきましょう。「認識精度90%以上」「処理時間を50%削減」など、後のステップで評価できる指標があると判断がしやすくなります。
課題を整理できたら、次に取りかかるのがデータの準備です。画像認識AIの精度は、学習や検証に使うデータの質と量に大きく左右されます。Rekognitionのような汎用APIを使う場合でも、精度検証のためのテスト用画像は必要ですし、SageMakerで独自モデルを構築するなら数百〜数千枚単位の学習用画像が求められるでしょう。
この段階でよくある落とし穴は、「画像データはあるが、整理されていない」というケースです。
フォルダ分けがバラバラだったり、画質にばらつきがあったり、ラベル付け(この画像が正常品か不良品かといった分類情報の付与)がされていなかったりと、データの整備だけで想定以上に時間がかかることも少なくありません。
プロジェクトの遅延を防ぐためにも、早い段階でデータの状態を確認しておくことをおすすめします。
②最適サービスの選定とPoC設計(期間:1〜2週間)
課題とデータが整理できたら、次はどのAWSサービスを使うかを決定し、PoC(概念実証)の設計を行うステップです。PoCとは、本格導入の前に小規模な検証を行い、実際に使い物になるかを確かめるプロセスのことを指します。
サービス選定の基本的な判断基準は、ここまでの章で紹介した内容をもとにまとめると以下のようになります。
| 解決したい課題 | 推奨サービス | 選定理由 |
|---|---|---|
| 一般的な物体・顔の認識 | Rekognition | 汎用モデルで即利用可能、開発不要 |
| 自社固有の画像分類・検出 | SageMaker | 独自データで高精度モデルを構築できる |
| 書類・帳票のデータ化 | Textract | 表・フォームの構造解析に特化 |
| 複数の課題を組み合わせ | 複数サービスの併用 | たとえばTextract+Rekognitionなど |
サービスを選んだら、PoCの設計に入ります。設計段階で決めておくべき事項は主に3つ。「検証に使うデータの範囲と量」「評価する指標と合格ライン」「検証期間とスケジュール」です。
PoCは小さく・速く回すのがポイントです。最初から完璧な精度を目指すのではなく、「このサービスで自社の課題が解決できそうか」という方向性の判断に集中しましょう。対象データを絞り込み、まずは数十〜数百枚程度の画像で試すだけでも、大まかな実現可能性は見えてきます。
③PoC実施と精度評価(期間:2週間〜1ヶ月)
設計が固まったら、いよいよPoCの実施です。選定したサービスに実際のデータを投入し、認識精度や処理速度を検証していきます。
Rekognitionを使う場合は、AWSのマネジメントコンソール(ブラウザ上の管理画面)からサンプル画像をアップロードするだけで、コードを書かずに基本的な検証が可能です。APIの呼び出し結果として返ってくるラベルや信頼度スコアを確認し、期待どおりの認識ができているかをチェックしていきます。
SageMakerを使う場合は、学習データの投入からモデルの構築・評価まで、より本格的な検証が必要になります。ここではエンジニアの関与が不可欠なため、社内にリソースがなければ外部パートナーとの協力体制を整えておくことが大切です。
PoC期間中に特に注意すべき点が3つあります。
1つ目は、精度だけでなくエッジケースを確認すること。 標準的な画像ではうまくいっても、照明が暗い画像、角度が極端な画像、ノイズが多い画像など、実運用で遭遇しそうな「難しいパターン」でどの程度の精度が出るかを必ず検証しましょう。
2つ目は、処理速度とコストの実測値を取ること。 カタログスペックだけでなく、自社のデータを使った実際の処理時間と費用を把握しておくと、本番運用時のコスト見積もりに役立ちます。
3つ目は、結果を定量的に記録すること。 「だいたいうまくいった」では判断材料になりません。正解率・誤検出率・処理速度などを数値で記録し、ステップ①で設定した成功基準と照らし合わせて、本格導入に進むかどうかを判断しましょう。
PoCの結果、精度が基準に達しない場合は、データの追加や前処理の改善、あるいはサービスの変更(Rekognitionで不十分ならSageMakerに切り替えるなど)を検討します。この段階での方向転換は、本番導入後の手戻りに比べればはるかに低コストで済むため、妥協せずに判断することが大切です。
④本番環境構築と運用開始(期間:1〜3ヶ月)
PoCで十分な成果が確認できたら、いよいよ本番環境の構築に移ります。このステップでは、検証段階のプロトタイプを実際の業務で安定して動く仕組みへと整えていく作業が中心です。
本番環境の構築で対応すべき要素は主に4つあります。
まず、システム連携の設計です。 画像認識の結果を既存の業務システム(基幹システム、データベース、管理画面など)にどう渡すかを設計します。たとえば、Textractで読み取った請求書データを自動的に会計ソフトに取り込んだり、Rekognitionの分類結果をECサイトの商品データベースに反映したりと、こうした連携部分の開発が必要になってきます。
次に、セキュリティとアクセス管理。 本番運用では、扱うデータの機密性に応じたセキュリティ設計が欠かせません。AWSのIAM(Identity and Access Management)を使ったアクセス権限の設定、データの暗号化、監査ログの設定などを適切に行いましょう。
3つ目は、監視とアラートの設定です。 画像認識AIは、運用を始めてからも精度の維持・管理が重要となります。処理エラーの監視、精度の定期的なモニタリング、異常が発生した際の通知体制を構築しておくことで、トラブルの早期発見と対処ができるようになるでしょう。
最後に、運用マニュアルと社内トレーニング。 最終的にシステムを使うのは現場の担当者です。操作手順書の作成や担当者向けの研修を実施しておくことで、導入後のスムーズな定着につながります。「ツールは完成したけれど、現場が使いこなせない」という事態は意外と起こりがちなため、この工程を省略しないことが成功のポイントです。
本番環境のリリース後も、定期的な精度チェックと改善サイクルを回し続けることが大切です。業務内容やデータの傾向は時間とともに変化するため、最初に構築したモデルがいつまでも最適とは限りません。運用しながら継続的に改善していく体制を、導入時点で計画に組み込んでおきましょう。
画像認識AIならニューラルオプト
ここまで解説してきたように、AWS画像認識の導入では「どのサービスを選ぶか」だけでなく、「課題の整理→PoC→本番構築→運用定着」という一連のプロセスを着実に進めることが成功の鍵を握ります。
しかし、社内にAIやクラウドの知見が十分にない場合、どこから手をつければよいか判断が難しいのも事実でしょう。
株式会社ニューラルオプトは、ChatGPTの日本展開にも携わるAI開発企業です。単なるシステム開発の受託ではなく、「そもそも何が課題なのか」というコンサルティングの段階から支援できるのが最大の特徴。
データサイエンスの知見を活かし、画像認識に限らずデータマイニングやテキストマイニングといった周辺領域も含めた最適な解決策を提案できます。
「失敗リスクを最小化する」をコンセプトに掲げており、課題起点での提案、組織への定着支援、運用開始後の継続的な改善まで一貫してサポートいたします。
「AWS画像認識を導入したいが、自社に合うサービスがわからない」「PoCから本番運用まで伴走してくれるパートナーを探している」という方は、ぜひ一度ニューラルオプトにご相談ください。
課題のヒアリングから、最適なサービス選定・開発・運用定着まで、トータルでお手伝いいたします。







