データは21世紀の原油とも言われるほど、現代のビジネスに欠かせない存在となっています。しかし、膨大なデータの山をただ眺めているだけでは、その本当の価値を引き出すことはできません。
データの中から隠れたパターンや法則性を見つけ出し、ビジネス上の意思決定に活かしていく。そのための強力な武器となるのが「データマイニング」です。
本記事では、データマイニングの概要から、製造、医療、金融、小売、教育など、様々な業界における活用事例まで幅広く紹介していきます。
OpenAIが展開するChat GPTの開発プロジェクト(日本語の強化学習)にも参画している株式会社ニューラルオプトの知見をもとに解説していきますので、ぜひ参考にしてみてください。


参考になるデータマイニングの活用事例8選
本記事で取り上げるデータアイニングの活用事例は以下のとおりです。
| 企業・団体名 | 概要 | 業界 |
|---|---|---|
| Mount Sinai Health System | 心不全患者の再入院率をデータマイニングで予測し、大幅に低減 | 医療 |
| Walmart(ウォルマート) | ビッグデータ分析基盤を構築し、需要予測の精度向上&売上変動をリアルタイムで把握 | 小売 |
| 韓国の大学病院 | 在院日数の要因を多変量解析し、病院オペレーションの最適化に成功 | 医療 |
| Netflix | 視聴履歴などから機械学習を活用し、個々ユーザーに最適化された作品を推薦 | エンタメ |
| 警察(米国・日本) | 犯罪データを解析し、将来の発生場所・人物を予測する「予測捜査」を導入 | 行政 |
| Alibaba(アリババ) | EC上の商品データを自動スキャンし、模倣品を高精度で検知&対策 | EC |
| Uber | 配車リクエストをデータ解析で最適化し、到着時刻や運賃をリアルタイム予測 | 交通・運輸 |
| AmazonほかEC企業 | ダイナミックプライシングで価格変動を自動把握し、効率的な価格戦略を展開 | EC |
1. 高精度の予測で収益性を改善|医療業界
1つ目の事例は、米国のMount Sinai Health System病院における再入院率予測の取り組みです。心不全患者の再入院率が高い課題がありましたが、データマイニングを導入することで予測精度の改善に成功しました。
導入前:現行の予測モデルの精度が不十分だった
再入院リスクが高い患者を見分けるためのモデルは既にありましたが、精度が低く30日以内の再入院率が16.66%と高止まりしていました。
再入院率が高いと医療の質や病院の収益性の低下につながるため、予測精度の高いモデルが求められていました。
導入後:データマイニングにより予測精度が大幅に向上
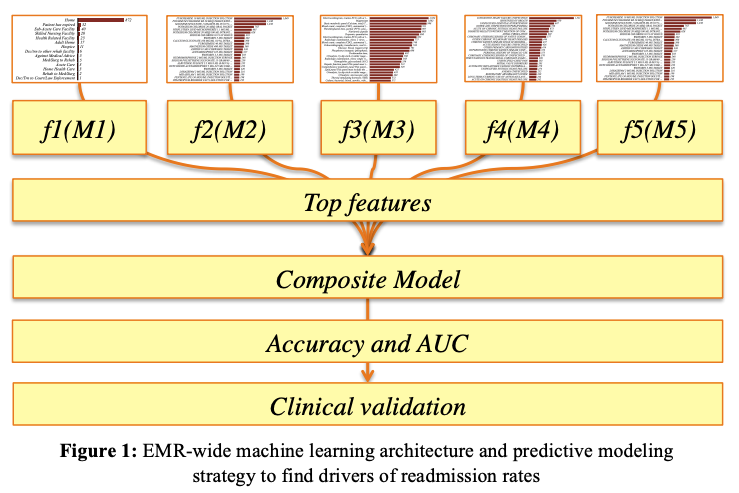
複数の要素を1つにまとめ、それぞれを機械学習で「再入院率」という1つの変数に回帰させる
参考:PREDICTIVE MODELING OF HOSPITAL READMISSION RATES USING ELECTRONIC MEDICAL RECORD-WIDE MACHINE LEARNING: A CASE-STUDY USING MOUNT SINAI HEART FAILURE COHORT
電子カルテの膨大なデータから4,205の特徴量を抽出し、機械学習を用いてモデル化。従来モデルに比べ格段に優れた予測精度を実現できました。
再入院リスクが高い患者を正確に判別できるようになることで、退院を遅らせたりさらに処置を行うなどが可能に。結果的に、病院の評判や収益性を悪化させる再入院率を大幅に下げることに成功しました。
このようにデータの力を最大限に活用することで、複雑な要因が絡むケースでも的確に予測できるようになります。
この病院の場合では、予防的な介入や退院後のケアの強化など、再入院防止に向けたアクションにつなげることができるでしょう。
2. 売上の急激な変化の要因を素早く特定|ウォルマート、需要予測
2つ目は、世界最大の小売業者であるWalmart(ウォルマート)のビッグデータ分析事例です。膨大な量の取引データを分析し、需要予測の精度向上を目指していましたが、分析に時間がかかり機会損失が発生していました。
そこで、高度な分析基盤を構築し、リアルタイムの分析を可能にしました。
導入前:週次や月次の売上分析では機会損失が発生していた
ある商品カテゴリーの売上が突然減少した際、原因究明に1週間以上を要したケースもありました。売上減少の兆候をいち早くキャッチし、迅速な対策を打つことができていませんでした。
導入後:リアルタイムのデータ分析により、異常をいち早く検知
Data Caféと呼ばれる分析基盤を構築。40ペタバイトという巨大なサイズの取引データを高速に処理し、可視化できるようになりました。
ハロウィーンのクッキーが2店舗で全く売れていないことをリアルタイムで把握し、在庫切れが原因だと突き止めて迅速に対応した例もあります。
このように、大量のデータをリアルタイムに分析することで、売上の変化をいち早くキャッチし、素早い意思決定と対策が可能になります。
膨大なデータを持つ企業ほど、スピード感を持ってデータを活用することが肝要だといえるでしょう。
3. 複雑な要因が絡む数値を予測|医療業界
2つ目は、韓国の大学病院で行われた在院日数の分析事例です。
在院日数は病院経営の効率性を表す重要な指標ですが、関連する複雑な要因を把握するのは容易ではありませんでした。そこで、データマイニングの力を借りて分析を行いました。
導入前:診療科や病名によって在院日数のばらつきが大きく、関連要因が不明瞭だった
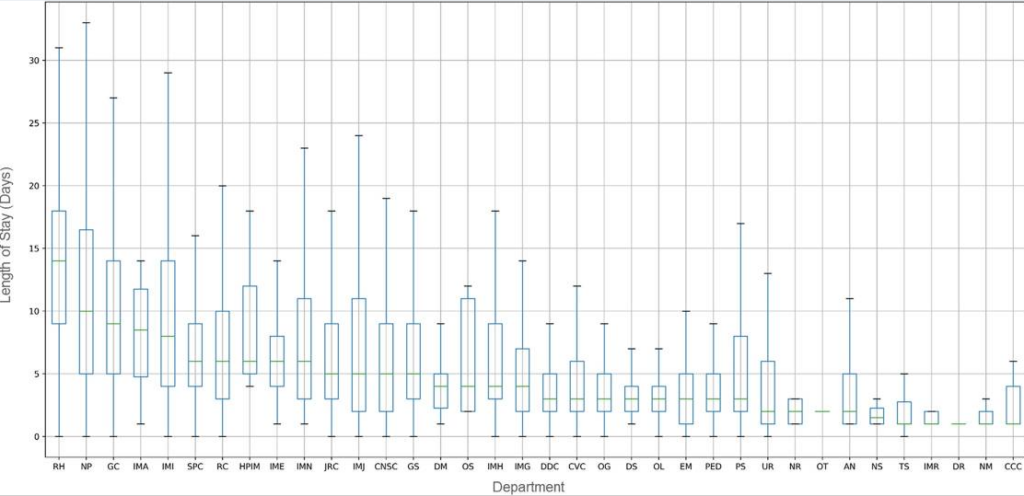
こちらは、病院の科ごとに平均在任日数の違いをグラフにしたもの。
平均在院日数が最も長いのはリハビリテーション科の15.9日。脳梗塞や心筋梗塞の診断では、在院日数が長くなる傾向がみられたためです。
導入後:在院日数に影響する幅広い要因を特定
データマイニングを行うことで、転科の有無、退院の遅れ、手術や診断の頻度、重症度、病床グレード、保険の種類など、多岐にわたる変数と在院日数の関連が明らかになりました。
患者ごとによる在院日数の予測ができるようになれば、病室の運用やスタッフの配置など、総合的に病院全体のオペレーションを改善できるように。結果的に収益性の改善ができるようになるでしょう。
このようにデータに基づいて分析すると、複雑な要因が絡みあった要素の予測が可能に。
関連要因を正しく理解し、プロセスの改善やモニタリングを進めることで、より効率的な管理・対策が可能となるでしょう。
4. 高精度なレコメンデーションで視聴維持率を向上|Netflix
4つ目は、世界最大の動画配信サービスNetflixのビッグデータ活用事例です。
Netflixは1億5100万人もの膨大な顧客を抱えていますが、93%という高い視聴維持率を誇っています。
視聴維持率はいわば「Netflixをどれだけ楽しんでくれているか」を示す指標であり、契約持続率など収益に大きな影響を及ぼす要素。
なぜ93%という極めて高い数字が実現できているのか。その背景には、ビッグデータ分析を駆使した精緻なレコメンデーションの仕組みがあります。
導入前:画一的なレコメンデーションでは顧客のニーズに応えきれなかった
動画のメタデータやジャンル情報などを基にしたルールベースのレコメンデーションでは、個々の顧客の嗜好に合わせたきめ細かな提案ができていませんでした。
コンテンツ数が増えれば増えるほど、顧客が自分に合った作品を見つけるのが難しくなっていました。
導入後:一人ひとりに最適化されたレコメンデーションを実現
視聴履歴、評価、検索履歴など、ユーザー行動から得られる多種多様なデータを分析。
機械学習を用いたレコメンデーションアルゴリズムにより、個々の顧客の好みを学習しパーソナライズされたお勧め作品を提示できるようになりました。
Netflixいわく、視聴の75%以上がこのレコメンデーションに基づいているとのこと。
つまりNetflixで作品を見る場合、75%がシステムにおすすめされたものを見ているということに。それだけ、レコメンデーションシステムがNetflixユーザーの体験創出につながっているということです。
コンテンツ制作の意思決定にもデータ分析が活かされており、視聴者のニーズを捉えたオリジナル作品を次々と生み出しています。
データの力を借りることで、エンターテイメントという主観的な分野であっても、顧客一人ひとりにフィットしたサービス提供が可能になります。
参考:How Netflix used big data and analytics to generate billion
5. 犯罪発生を予測する「予測捜査」|犯罪予測
9つ目は、日米の警察が導入を進める「予測捜査(Predictive Policing)」についてです。過去の犯罪データを分析し、AIを用いて将来の犯罪発生場所や内容、犯人を予測するシステムです。
『マイノリティ・レポート』や『PSYCHO-PASS』の世界を彷彿とさせる取り組みですが、警察は真剣に効果を期待しており、ベンダー企業も新たなビジネスチャンスと捉えています。
導入前:経験と勘に頼った犯罪予測と人員配置に課題があった
従来の犯罪予測は、熟練警官の経験則に基づくところが大きく、客観性や再現性に乏しい面がありました。
また、人的リソースの制約から、パトロールなどの配置も非効率的になりがちでした。市民の安全という最優先事項の実現には、より高度な犯罪予測と予防が求められていました。
導入後:ビッグデータとAIにより高精度な犯罪予測を実現
Palantir社やPredPol社など、予測捜査ツールを提供するベンダーが台頭。各地の警察で導入が進んでいます。
犯罪統計、地理的条件、人口動態など、多様なデータを機械学習で分析。犯罪多発地域やリスクの高い人物を特定し、パトロールなどの予防策に役立てることが可能です。
予測に使用する個人情報のリスクはあるものの、治安という国の問題の改善にも役立てられるのはデータマイニングの凄さであると言えます。
参考:犯人を予測する予測捜査システムの導入が進む日米 その実態と問題とは
6. 膨大な取引データから模倣品を検知|アリババ、模倣品対策
最後は、中国ECの雄であるアリババグループによる模倣品対策の取り組みです。
アリババは、傘下のECプラットフォーム上で取引される膨大な商品データを分析。
機械学習を駆使して模倣品を検知し、店舗閉鎖や法的措置につなげています。模倣品は権利者の利益を損なうだけでなく、消費者の信頼をも損ねる大きな問題だからです。
導入前:人力での模倣品パトロールには限界があった
アリババのプラットフォームでは、日に1,000万点もの新商品が出品されます。
これほどの膨大な商品を、目視で一つ一つチェックしていくのは不可能に近い作業です。
模倣品業者の巧妙な手口にも対応しきれず、すり抜けるケースが少なくありませんでした。ブランドオーナーからの強い改善要求にも迅速に応えられない状況でした。
導入後:ビッグデータ分析とAIで高精度な模倣品検知を実現
アリババは「クラウドソード」と呼ぶ模倣品対策システムを開発。商品の価格や説明文、画像、取引記録など、100以上の要素を分析し、疑わしい商品を自動検知します。
OCR技術も駆使し、画像内のブランドロゴと商品説明文の不一致なども見抜きます。模倣品の疑いがある場合は、店舗への警告や閉鎖、法執行当局への通報などにつなげます。
模倣品取引の背後関係の追跡にもビッグデータ分析が一役買っています。
商品情報や資金の流れなどを分析し、模倣品の製造元や経路の特定を支援。当局と連携した摘発にもつなげています。
参考:Counterfeiters Can Run, But Can’t Hide from Alibaba’s Big Data
はい、失礼しました。日本語で説明しましょう。
7. 革新的な配車アルゴリズムで世界を席巻|Uber
運輸業界のリーダーとして、アメリカのUberはデータサイエンスの成功例の最たるものです。このケーススタディでは、Uberが大規模なロジスティクスを最適化するために使用している具体的な手法について掘り下げていきます。
導入前:何百万もの乗車を調整するという複雑な課題
Uberは、1回の乗車ごとに膨大なデータ処理の課題に直面しています。ユーザーの位置情報に基づいて運転手の到着予定時間を見積もる一方で、交通状況を考慮し運賃を計算する必要があります。
これには、位置情報データ、ユーザー情報、金融データ、リアルタイムの交通情報を、毎月何百万もの取引でシームレスに統合することが必要。
データマイニングの活用なしに手動で計算するのはまず不可能であると言えます。
導入後:データマイニングで到着時刻・運賃を予測
Uberは、地域ごとに異なる要因を重み付けする独自のアルゴリズムを採用しています。GPSなどの高度な相関分析により、最寄りのドライバーと最適なルートを特定します。
こうすることで、「配車を頼もうとした時点で到着予測時刻と運賃が分かる」という革命的なシステムが可能になりました。
さらに機械学習、人工知能、ルート最適化アルゴリズムを組み合わせ、リアルタイムデータを絶えず取り込んでいます。交通渋滞の緩和や配車効率の向上にもつながっています。
公共交通網が未発達なアメリカでは、Uberがもたらした交通革命は大きなもの。Uberはアメリカでは支配的なシェアを誇る交通系サービスですが、この裏にはこういったデータマイニングの活用が隠れているのです。
8. ECサイトの価格を自動で収集|Amazonなど
最後は、アマゾンに代表されるECサイトにおける価格変動のモニタリングについてです。
需要や競合他社の価格など、様々な変数に基づいて一日に何度も製品価格が変動する「ダイナミックプライシング」が一般的になる中、価格推移を把握することが競争力維持の鍵を握ります。
実際に、こういったECプラットフォーム上の販売業者の多くがWebスクレイピングサービスを活用し、リアルタイムの価格変化を追跡しているのです。
導入前:手作業での価格調査は非効率で精度にも課題がある
かつては、競合他社のWebサイトを定期的に訪問し、手作業で価格をチェックするのが一般的でした。
しかし、この方法では膨大な工数がかかるうえ、頻繁な変動を見逃すリスクもありました。
日に何度も価格が変わる時代にあって、より効率的かつ正確な価格把握が求められていました。
導入後:自動化されたデータ収集により、リアルタイムの価格分析が可能に
Webスクレイピングを活用することで、競合他社のWebサイトから製品価格を自動的に抽出。リアルタイムの価格推移データを効率的に収集できるようになりました。
ECにおいて、価格設定は売上を左右する大きな要因。普段何気なく使用しているAmazonなどのECサイトですが、その裏ではこういったデータマイニングが隠れています。
実際、データマイニング・AIを用いて需要や競合状況を分析し、最適な価格設定を提案するツールも登場しています。
データマイニングでできること
データマイニングを活用することで、以下のようなことが可能になります。
- データの分類
- データ間の関連性の発見
- 将来の結果予測
- 異常値の検出
- テキストデータからの情報抽出
データマイニングの大きな特徴は、膨大なデータの中から隠れたパターンや関係性を見つけ出す点にあります。たとえば、顧客情報と販売データを組み合わせて分析することで、ある商品を購入する可能性の高い顧客層を特定できるかもしれません。これは「データの分類」の一例です。
また、一見関連性がなさそうなデータ同士の関係性を発見することも、データマイニングの得意分野です。たとえば、ある商品を購入した顧客は、別のある商品も購入する傾向が高い、といった具合です。
そして、過去のデータの関係性をもとに、将来起こりうる結果を予測することも可能です。これを「将来の結果予測」と呼びます。販売データと在庫データから需要を予測し、適切な発注量を決める、といったことが代表的な活用例でしょう。
さらに、データマイニングでは「異常値の検出」もできます。機械の稼働データから故障の予兆を察知したり、クレジットカードの不正利用を見抜いたりするのに役立ちます。
加えて、レビューやSNSの投稿など、テキストデータからも有益な情報を取り出せます。この「テキストデータからの情報抽出」は、テキストマイニングと呼ばれ、昨今ますます注目を集めています。
テキストマイニングについては、以下の記事を参考にしてみてください。
テキストマイニングとは?できることや手法、導入をAI開発会社が解説
■少しでもAI・システム開発やPoCに興味があれば、まずはお気軽にご相談ください。目的・課題を伺ったうえで、弊社から手堅く進める方法・お見積りをお伝えさせていただきます。
AIシステム開発サービスのお問い合わせはこちら>>
AIシステム開発サービス概要資料のダウンロードはこちら>>
AIシステム開発サービスの詳細はこちら>>
AIシステム受託開発
相談だけで発注しなくても構いません。

データマイニングの業界別活用例
データマイニングは幅広い業界で活用され、ビジネスに大きなインパクトをもたらしています。
膨大なデータの中から価値ある情報を見出し、意思決定や問題解決に役立てる。それがデータマイニングの真骨頂です。
ここでは、代表的な業界におけるデータマイニング活用例を見ていきましょう。
製造業界
製造業界では、データマイニングにより以下のようなことが可能です。
- 設備の故障予測や予防保全
- 製品の品質管理と不良品の削減
- 製造工程の最適化によるコスト削減
例えば、センサーから収集した設備の稼働データを分析することで、故障の兆候を早期に検知できます。そうすることで、突発的な設備停止を未然に防ぎ、計画的なメンテナンスを実施できるのです。
また、製造工程で発生する膨大な品質データを分析し、不良品の発生パターンを見極めることも可能です。原因究明と再発防止を進めることで、品質の向上とコストの削減を同時に実現できます。
さらには、工程ごとの処理時間や在庫量などのデータを分析し、ボトルネックの特定や最適な生産計画の立案にも役立てられます。
医療業界
医療業界では、データマイニングにより以下のようなことが可能です。
- 診断精度の向上と医療ミスの削減
- 新薬の開発や治験の効率化
- 副作用の早期発見と予防
患者の症例データや検査結果など、大量の医療データを機械学習で分析することで、疾患と症状の関連性や治療法ごとの予後の違いが明らかになります。
さらに、市販後の医薬品についても、電子カルテなどから副作用の発生傾向をいち早く捉えることで、被害の拡大を防げます。
金融業界
金融業界では、データマイニングにより以下のようなことが可能です。
- 与信管理の高度化によるリスク低減
- 不正取引の検知と防止
- マーケティングの最適化と収益向上
クレジットスコアリングに代表される与信管理は、データマイニングの代表的な活用シーンです。申込者の属性や過去の取引履歴などを分析し、デフォルト率を予測することで、リスクに見合った融資可否の意思決定ができます。
また、クレジットカードの不正利用や、マネーロンダリングなどの金融犯罪の検知にもデータマイニングは威力を発揮します。異常な取引パターンをリアルタイムで検知し、速やかに対処することで、被害を最小限に抑えられるのです。
小売・EC業界
小売・EC業界では、データマイニングにより以下のようなことが可能です。
- 需要予測の高度化と在庫最適化
- レコメンデーションの精度向上
- 購買行動の分析と販促施策の最適化
販売データを分析して商品ごとの需要を正確に予測することで、欠品のロスを減らしつつ、在庫の適正化も実現できます。需給のミスマッチ解消は、収益性に直結する重要課題だからです。
また、購買履歴や閲覧履歴などを分析し、一人ひとりの嗜好に合わせた商品レコメンドを行うことで、顧客満足度とエンゲージメントの向上、ひいては客単価のアップにつなげられます。
さらには、販売データと顧客属性を掛け合わせることで、購買行動の背後にある要因が見えてきます。そこから導き出される仮説に基づいて、商品開発や品揃え、販促施策の最適化を図れるのです。
教育業界
教育業界では、データマイニングにより以下のようなことが可能です。
- 生徒一人ひとりの理解度や苦手分野の可視化
- 個に最適化された学習コンテンツの提供
- 教材や指導法の効果検証と改善
生徒の成績データや学習ログなどを分析することで、一人ひとりの理解度や つまずきポイントが明らかになります。
そうした分析結果を踏まえ、個別最適化された学習課題を提示したり、復習用の教材を用意したりと、手厚いフォローが可能になるのです。
また、アダプティブラーニングの仕組みを取り入れることで、生徒の反応を見ながら、難易度や説明の仕方を自動調整する。個に応じた学びを実現できます。
授業評価アンケートの分析や、成績データの経年比較などを通じて、教材や指導法の効果検証もできます。エビデンスに基づく指導改善サイクルにより、教育の質を高められるのです。
データマイニングの活用・開発ならニューラルオプト
データマイニングの活用でお困りの方は、ニューラルオプトにご相談ください。弊社は、OpenAIが展開するChatGPTの強化学習プロジェクトにも携わっており、機械学習やデータ活用に高い専門性を有しています。
弊社はコンサルティング会社でもあるため、そもそもデータマイニングを行う必要があるのか、どのような課題解決を目指すのか、そうした大局観を持って、分析の目的や手法・体制づくりまで丁寧にアドバイスいたします。
まずはお気軽にご相談いただければ幸いです。







