企業にとって顧客の声は経営の羅針盤であり、大切な資産です。しかし、膨大な量の顧客の声をどのように分析し、活用していけばよいのでしょうか。その有力な手段となるのが「テキストマイニング」です。
本記事では、テキストマイニングの概要や分析手法について解説するとともに、実際の活用事例を詳しく紹介します。
OpenAIが展開するChat GPTの開発プロジェクト(日本語の強化学習)にも参画している株式会社ニューラルオプトの知見をもとに解説していきますので、ぜひ参考にしてみてください。


テキストマイニングとは文章から有用な情報を抽出する方法
テキストマイニングとは、大量の文章データから有用な情報を抽出する技術です。
SNSの投稿やアンケートの自由回答など、非構造化データと呼ばれる自然言語で書かれたテキストを分析の対象とします。
自然言語処理の手法を用いて、文章を単語や文節に分割したうえで、出現頻度や相関関係を分析することで、隠れたトレンドや知見を発見します。
主に以下のような方法で、文章から有用な情報を取り出します。
- 頻出語の抽出:どのような単語がよく使われているかを調べ、話題の傾向をつかむ
- ワードクラウド:抽出した頻出語を視覚的に表現し、直感的に理解しやすくする
- 共起ネットワーク:単語同士の結びつきの強さを可視化し、テーマ間の関係性を探る
- センチメント分析:文章に含まれるポジティブ・ネガティブな感情を数値化する
これらの分析を組み合わせることで、大量の文章の中に埋もれている有益な情報を効率的に見つけ出すことができます。例えば、商品レビューを分析すれば、お客様の生の声から改善のヒントが得られるかもしれません。
必要なデータ量は目的により異なる
テキストマイニングに必要なデータ量は、分析の目的によって異なります。
おおまかな傾向をつかむだけなら、数百〜数千件程度の文章でも一定の成果は期待できるでしょう。
一方、センチメント分析のように文章の細かいニュアンスを判別したい場合は、学習用のデータとして数千〜数万件規模のテキストが必要になることもあります。
分析にはある程度まとまった量のデータが必要ですが、最初から完璧を目指す必要はありません。まずは手元にあるデータで分析を始め、徐々にデータを増やしていくのがよいでしょう。
分析を繰り返すことで、質の高い学習データが蓄積され、分析の精度も向上していきます。
テキストマイニングでできること・活用例
テキストマイニングを活用すると、大量の文章データから様々な知見を引き出すことができます。
ここでは、テキストマイニングの代表的な活用例を5つご紹介します。
- 感情や評価を見える化できる
- 顧客の声から改善点を抽出する
- マーケティング・企画への活用
- FAQ・マニュアルの整備
- 学術分野で知識を抽出する
1. 感情や評価を見える化できる
センチメント分析により、テキストに含まれるポジティブ・ネガティブな感情を定量的に把握できます。
これを顧客の口コミやレビューに適用すれば、製品やサービスに対する満足度や評判を測定可能。改善すべきポイントが明らかになり、的確なアクションにつなげられます。
2. 顧客の声から改善点を抽出する
アンケートの自由回答欄、コールセンターの問い合わせ記録、レビューサイトの口コミなど、日々の業務で集まる膨大なテキストデータ。
テキストマイニングを使えば、そこから顧客の生の声を拾い上げ、製品やサービスに求められている機能・要望を可視化できます。
その結果、リニューアルや新商品開発の成功率アップ、顧客満足度の向上、クレーム削減などが期待できるでしょう。
3. マーケティング・企画への活用
既存顧客や見込み顧客の声を詳細に分析することで、新商品のコンセプトづくりやペルソナ設計に役立てられます。また、キャンペーンの反響をテキストマイニングで評価すれば、効果測定を定量・定性の両面から行えます。
これらの情報を基に、商品開発のヒット率を高めたり、プロモーション施策を最適化したり、ターゲットとなるセグメントを明確にしたりと、マーケティング・企画業務に幅広く活用できるでしょう。
4. FAQ・マニュアルの整備
サポートセンターの対応ログや問い合わせメールをテキストマイニングすることで、頻出する質問や回答すべき内容が自動的に抽出できます。
それを基にFAQを整備したり、チャットボットに組み込んだりできるため、サポートコストの削減につながります。
また、現場の担当者が都度回答していた内容を一元管理できるので、ノウハウの属人化解消や業務効率化にも役立ちます。
5. 学術分野で知識を抽出する
学術分野では膨大な数の論文やレポート、学会発表資料などが日々生み出されています。これらをテキストマイニングで分析することで、最新の研究動向や関連分野のトレンドを俯瞰的に把握できます。
また、将来有望なテーマやコラボレーション先の発見にもつながるでしょう。
膨大な文献を人力だけで処理するのは困難ですが、テキストマイニングを使えば知識を効率的に抽出し、研究開発のスピードアップや新たな着想を得るためのベースを構築できます。
■少しでもAI・システム開発やPoCに興味があれば、まずはお気軽にご相談ください。目的・課題を伺ったうえで、弊社から手堅く進める方法・お見積りをお伝えさせていただきます。
AIシステム開発サービスのお問い合わせはこちら>>
AIシステム開発サービス概要資料のダウンロードはこちら>>
AIシステム開発サービスの詳細はこちら>>
AIシステム受託開発
相談だけで発注しなくても構いません。

テキストマイニングが活用できるケース
企業が日々の業務で収集・蓄積している大量のテキストデータは、宝の山といえるでしょう。これらをテキストマイニングで分析することで、ビジネスに役立つ様々な知見を引き出せます。
ここでは、テキストマイニングが特に力を発揮する3つのケースを見ていきましょう。
- 顧客の声を効率的に分析したい
- 顧客の悩み・疑問を洗い出したい
- SNSでの評価を把握したい
ケース1. 顧客の声を効率的に分析したい
コールセンターへの問い合わせ、アンケートの自由回答、ユーザーレビューなど、顧客の生の声が詰まったテキストデータは企業にとって非常に価値があります。
しかし、膨大な量になるとすべてに目を通すのは現実的ではありません。
そこでテキストマイニングの出番です。
自然言語処理技術を使って大量のテキストを自動的に分析し、頻出するキーワードや話題を抽出。顧客のニーズや課題を効率的に把握できます。
この気づきを基に、製品・サービスの改善点を見つけたり、新たな施策を立案したりできるでしょう。
ケース2. 顧客の悩み・疑問を洗い出したい
テキストマイニングは、顧客の抱える悩みや疑問を探るのにも役立ちます。例えば、サポートセンターに寄せられる質問をテキストマイニングで分析すれば、よくある質問や回答に困る質問が明らかになります。
そうした情報を基にFAQを拡充したり、マニュアルを見直したりできます。
また、問い合わせの傾向から製品の弱点や不明点も見えてくるはず。顧客目線に立った使い勝手の向上や、説明不足の解消などにつなげられるでしょう。
ケース3. SNSでの評価を把握したい
TwitterやFacebookなどのSNSには、自社や競合他社の製品・サービスに関する率直な感想が数多く投稿されています。これは、顧客の本音を知る貴重な情報源。
SNSの投稿をテキストマイニングすることで、自社の評判がどうなっているか、競合と比べてどんな強み・弱みがあるかなどを客観的に把握できます。
例えばセンチメント分析によって、ポジティブ・ネガティブな評価の割合を定量化。時系列で評価の変化を追ったり、競合比較をしたりすることで、自社の立ち位置が見えてきます。
また共起ネットワークを使えば、自社や競合に関連して語られるキーワードのつながりも可視化できるでしょう。こうした分析結果を基に、打つべき施策や改善策を検討できます。
テキストマイニングの手法
テキストマイニングには様々な分析手法があります。それぞれ目的や状況に応じて使い分けることが大切です。ここでは代表的な6つの手法について、わかりやすく解説していきましょう。
- 頻出語分析(何が一番語られているか)
- 共起分析(関連する疑問・課題はなにか)
- センチメント分析(感情や評判はどうか)
- 対応分析(複数の要素間の関係はどうか)
- 主成分分析(少数の軸にグループ化する)
- クラスタリング(類似度をもとにグループ化する)
頻出語分析(何が一番語られているか)
頻出語分析は、テキストデータの中で最も多く出現する単語を抽出し、その頻度をカウントする手法です。
例えば、顧客アンケートの自由回答欄で「価格」「デザイン」「対応が遅い」などのキーワードが頻繁に現れていれば、それらが顧客の関心事だと推測できます。
頻出語分析は、大量のテキストから話題の中心を素早くつかむのに適しています。この手法を使えば、まず顧客が何を気にしているのかの第一印象を得られるでしょう。そこから課題を発見し、より深い分析へと進むことができます。
頻出語を調べる際のコツは、単語の細かなバリエーション(例: 「高い」「高すぎる」「高価」など)を適切にまとめることです。同じ意味を表す表現を集約しないと、本当に重要なキーワードが埋もれてしまう恐れがあります。
共起分析(関連する疑問・課題はなにか)
共起分析は、ある単語と一緒によく出現する単語を見つけ出す手法です。
つまり、単語と単語の結びつきの強さを数値化するわけです。例えば、製品レビューで「電池」と「すぐ切れる」の共起が目立つ場合、バッテリーの持続時間に問題があると推察できるでしょう。
頻出語分析が単語の出現回数だけに注目するのに対し、共起分析ではキーワード間の関係性に着目します。
これにより、「○○が高い」「○○で不便」といった、ユーザーの不満や要望のパターンを発見しやすくなります。
共起の強さは、単語ペアの出現回数だけでなく、全体の中での出現割合(確率)も考慮して算出します。2つの単語がたまたま同じ文章中に出てきただけなのか、それとも意味的に強い結びつきがあるのかを見極めるためです。
センチメント分析(感情や評判はどうか)
センチメント分析は、文章に含まれる感情(ポジティブ・ネガティブ)を判定する手法です。すなわち、書き手の感情や評価を数値化するわけです。
分析には、感情辞書やルールベース、機械学習など複数のアプローチがあります。
例えば、「最高」「素晴らしい」などのポジティブな単語と、「最悪」「がっかり」などのネガティブな単語をあらかじめ辞書に登録しておき、それらの出現頻度から感情を判断する方法があります。
文脈によっては感情の読み取りが難しいケースもありますが、およそのポジネガ傾向は把握できるでしょう。センチメント分析を使えば、自社製品の良し悪しや、ユーザーの満足度を定量的に評価できます。
対応分析(複数の要素間の関係はどうか)
対応分析は、行と列からなるクロス集計表を2次元マップ上にプロットし、その近さ(対応関係)を視覚化する手法です。
例えば、購買データを「性別(男女)」と「商品カテゴリ(A, B, C)」で集計し、対応分析にかけると以下のようになります。
- 「男性」と「カテゴリA」が近くに布置される → 男性はカテゴリAをよく買っている
- 「女性」と「カテゴリC」が近くに布置される → 女性はカテゴリCを好んで買っている
このように、行(属性)と列(キーワード)がお互いにどう関連しているかを一目で把握できるのが対応分析の強みです。ユーザーの属性別に、どんな言葉が特徴的に使われているかを知りたいときに便利な手法といえます。
ただし、データの次元が増えると解釈が難しくなるため、属性やキーワードの数が多すぎる場合は事前に絞り込むことをおすすめします。
主成分分析(少数の軸にグループ化する)
主成分分析は、多次元のデータ(例: 100個の単語の出現頻度)を、情報をなるべく失わずに少数の次元(2~3個の総合指標)に要約する手法です。
もとのデータがバラバラに分布していても、主成分分析によって全体の特徴をつかみやすくなります。
例えば、100種類の単語をそれぞれ1つの軸とみなすと、100次元空間上の1点としてデータを表現できます。
主成分分析を適用すると、それが2~3個の合成変数(主成分)に集約されるイメージです。各主成分は、もとの単語の重み付き線形結合として表されます。
主成分分析を使えば、多次元データの全体像を視覚的に捉えられます。また、類似したデータ同士が主成分空間上で近くに集まるため、グループ分けすることも可能です。データ全体の「見取り図」を描きたいときに役立つ手法だと言えるでしょう。
クラスタリング(類似度をもとにグループ化する)
クラスタリングは、似たもの同士を自動的にグループ化する手法の総称です。似ている度合い(類似度や距離)を定義し、それに基づいてデータをまとめるのが特徴です。
テキストマイニングでは、文書を単語の出現パターンで表現(ベクトル化)し、その類似度を使ってクラスタリングします。例えば、ユーザーレビューを「満足度が高いグループ」「改善要求が多いグループ」のように、テーマ別に自動で分類できます。
代表的なクラスタリング手法としては、k-means法や階層的クラスタリングなどが挙げられます。クラスタ数をあらかじめ決めるか、データに応じて自動で決めるか、アルゴリズムによって異なります。
大量のテキストをざっくりと分類し、グループごとの特徴を把握したいときに便利なのがクラスタリングです。主成分分析と組み合わせれば、各クラスタがどんな単語を含み、互いにどう異なるのかを視覚的に理解しやすくなるでしょう。
テキストマイニングを活用した成功事例
ここからは、実際にテキストマイニングを活用した成功事例を見ていきましょう。
- Amazonの価格設定分析
- Fitbitのカスタマーサポート改善
- 人身売買の捜査支援
なお、事例については以下の記事でも詳しく取り上げています。
テキストマイニングの導入成功事例8選!ビフォー・アフターを紹介
1. Amazonの価格設定分析
Amazonでは、消費者の声を徹底的に活用することで、適切な商品開発や価格設定を行っています。
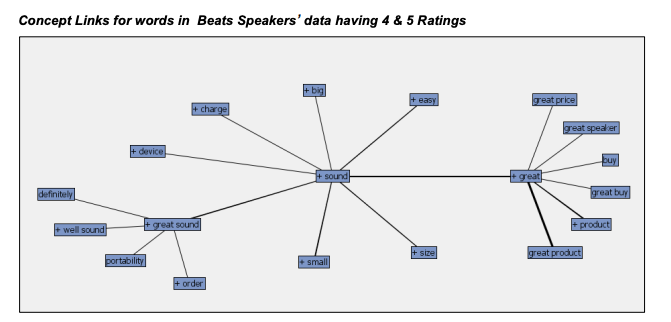
ある若手アナリストチームが、$150という価格帯で選ぶときに最適なスピーカーを知るために、テキストマイニングを実施しました。
彼らは、人気ブランドの5つのスピーカーについて、Amazon上のレビューデータを抽出。これには、消費者の評価、価格、レビュー本文が含まれていました。
出典:Analyzing Amazon’s Customer Reviews using SAS® Text Miner for Devising Successful Product Launch Strategies
評価点数とレビュー内容を紐付けて分析することで、スピーカーの「音質」「バッテリー寿命」「素材」「充電ポート」といった要素が、高評価を左右することが明らかになりました。
逆に、低評価の原因は「ノイズ」や「価格」であることもわかりました。
この結果を基に、Amazonでは以下のようなアクションにつなげています。
- 高評価要因を押さえた商品開発。音質や使いやすさなど消費者の重視ポイントを外さない。
- 低評価要因の改善。防音性を高めたり、コストダウンによる価格改定を検討。
- レビュー内容に即した的確な商品説明文の作成。購入検討中のユーザーにアピール。
テキストマイニングにより、消費者の生の声を可視化し、それを次の施策に活かせるようになったのです。商品の企画・開発から、プロモーション、価格設定に至るまで、幅広い場面での意思決定がスムーズになりました。
2. Fitbitのカスタマーサポート改善
ウェアラブル端末であるFitbitでは、SNSを通じた顧客対応に力を入れています。特にTwitterでは、1分に1件のペースでユーザーからの問い合わせが@FitbitSupportに寄せられます。
従来、これらのツイートを目視で確認し、個別に返信する対応が行われていました。しかし件数が膨大なため、対応漏れや見落としも発生。また、全体の傾向をつかむのも難しい状況でした。
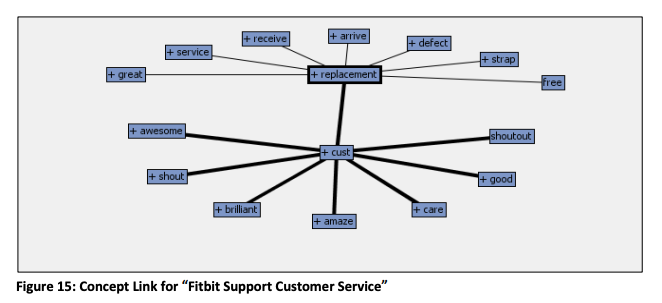
そこでFitbitでは、ツイートの内容をテキストマイニングで分析。
参考:Using SAS® Enterprise Miner for Categorization of Fitbit’s Customer Complaints on Twitter
参考:Using SAS® Enterprise Miner for Categorization of Fitbit’s Customer Complaints on Twitter
「アクティビティ記録」「端末のデザイン」「アプリの操作性」など、問い合わせ内容を自動で分類できるようにしました。これにより、以下のような改善を実現しています。
- リアルタイムに問題を検知し、速やかな対応が可能に。放置による顧客離れを防止。
- 端末の不具合など、多発する問題を特定。設計や品質管理にフィードバック。
- 新製品への評価を即座に把握。改良点を見出し、次期モデル開発に活かす。
Tweet分析の精度は73%に達しており、顧客の生の声を業務改善に役立てられるレベルになっています。サポートの質と速度を高めるとともに、顧客目線での商品開発にもつながっているのです。
参考:Using SAS® Enterprise Miner for Categorization of Fitbit’s Customer Complaints on Twitter
3. 人身売買の捜査支援
世界では4000万人以上が人身売買の被害に遭っています。
特に子供は弱い立場に置かれがちで、Crime Prevention団体のトム・サボ氏は、人身売買に関するシンポジウムに参加したことをきっかけに、テキストマイニングを使った捜査支援に取り組み始めました。
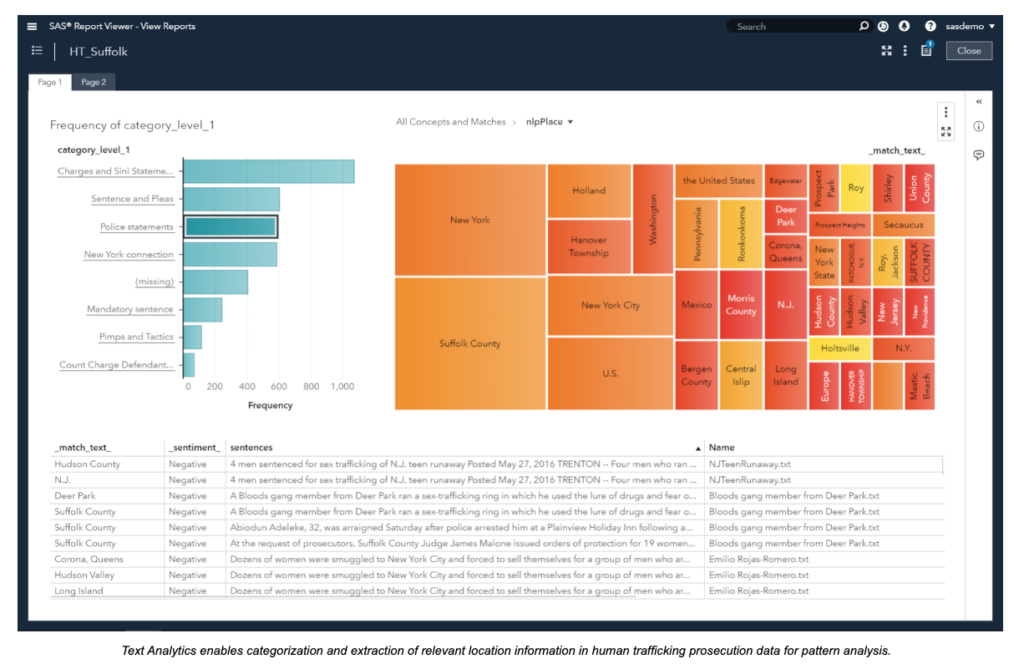
サボ氏は、警察のレポート、新聞記事、裁判記録、怪しげな広告サイトなど、複数の文書データを統合。関連性の高いパターンを抽出し、予測分析モデルに組み込みました。
例えば、ニューヨークの警察情報を分析したところ、州外や国外とのつながりが浮かび上がってきました。これにより、事件に関与している人物や発生しやすい場所を特定できるようになりました。
参考:Countering human trafficking using text analytics and AI
この分析モデルを使うことで、以下のような効果が生まれています。
- 人身売買の兆候を早期に発見。被害が深刻化する前に介入できる。
- 犯罪グループのつながりを把握。組織の全容解明や検挙につなげられる。
- 過去事例の傾向から、重点的に監視すべきエリアを割り出せる。
もちろん、プライバシーへの配慮は欠かせません。個人情報の扱いには細心の注意を払う必要があります。それでも、データの力を捜査に活用することで、人身売買のような深刻な犯罪の撲滅に近づけるはずです。
参考:Countering human trafficking using text analytics and AI
テキストマイニングができるツール
テキストマイニングを実践するには、適切なツールの力を借りるのが賢明です。
手作業では膨大な時間と労力がかかりますが、ツールを使えば効率的かつ高度な分析が可能になります。テキストマイニング向けのツールには、大きく分けて以下の3タイプがあります。
専用のソフトウェア
テキストマイニングに特化した商用・オープンソースのソフトウェアも数多く存在します。例えば、以下のようなツールが代表的です。
- Text Mining Studio
- KH Coder
- IBM SPSS Modeler
- SAS Text Miner
これらのソフトウェアは、テキストデータの前処理(クリーニングや形態素解析など)から、各種分析手法の適用、結果の可視化までを一貫して行えるのが特徴です。プログラミングの知識がなくても、GUIベースで操作できるものが多いです。
ただし無料で使えるツールは少なく、導入コストがかかる場合があります。また、機能や分析手法が固定されているため、カスタマイズの自由度は低めです。
テキストマイニングをとりあえず業務に取り入れたい企業におすすめのツールだと言えます。分析のノウハウが社内にない場合でも、一定レベルの分析を安定して行えるでしょう。
プログラミングライブラリ
Python や R といったプログラミング言語には、テキストマイニングに使える優れたライブラリ(パッケージ)が豊富に用意されています。
例えば、以下のようなものがよく知られています。
- Python: scikit-learn、pandas、NLTK、spaCy、gensim など
- R: tidytext、tm、quanteda など
これらのライブラリを使えば、データの読み込みから前処理、分析、可視化まで、プログラムを組んで自由自在に行えます。最新の分析手法にもいち早く対応できるのが魅力です。
ただし、ある程度のプログラミングスキルが必要なのは言うまでもありません。実装方法を一から調べなければならない場合もあるでしょう。使い方を習得する学習コストは少なくありません。
とはいえ、分析の自由度や柔軟性は抜群です。新しい手法を試したい、独自の分析フローを組みたいという人におすすめです。分析ロジックを細かくカスタマイズできるのは、プログラミングならではの強みと言えます。
Excel連携ツール・プラグイン
Excelと連携して使えるツールやプラグインも存在します。例えば、以下のようなものがあります。
- Tenjin(ユーザーローカル社の無料アドイン)
- テキストテーブル for Excel(オープンソースのアドイン)
Excelでテキストマイニングと聞くと意外に思うかもしれませんが、それほど難しい操作は必要ありません。通常のExcel関数を組み合わせたり、上記のようなアドインを使えば、シンプルな分析は十分行えます。
Excelはビジネスパーソンにとって最もなじみ深いツールの一つです。「プログラミングはちょっと…」という人でも、Excelなら抵抗なく使えるのではないでしょうか。
少ない学習コストで、手っ取り早く分析をスタートできるのは大きなメリットです。
もちろん、本格的な分析をするには機能面での限界があります。しかし、まずは気軽に始めてみたい、データの概要をざっと知りたいという場合には、検討に値するでしょう。
テキストマイニングなどのAI開発ならニューラルオプトへ
昨今、デジタルトランスフォーメーション(DX)への関心が高まっていますが、その成否を握るのはデータ活用力だと言っても過言ではありません。
しかし、闇雲に最新ツールを導入しても、本質的な課題解決には至りません。適切な目的設定とデータ選定、分析プロセスの設計など、AIプロジェクトを成功に導くためのノウハウが不可欠です。
弊社は、テキストマイニングをはじめとするAI開発を得意としています。
OpenAIが展開するChatGPTの開発プロジェクト(「RLHF」という手法の開発)にも参画しており、コンサルティング会社でもあるため「そもそもAIを使う必要があるのか」「どういった課題解決を図るのか」といった大局的な視点からサポートさせていただきます。
お困りの方はぜひご相談ください。







